Workflow for Deep Learning Projects
Anything that can go wrong will go wrong
Deep learning projects often follow Murphy’s Law - Anything that can go wrong with neural networks will almost always go wrong. They fail easily and, the worst of all, silently. Any standard program will fail at the first inconsistency in logic. But a neural network will continue to work even when you have misconfigured something. The correctness of neural networks is on a spectrum. To ensure correctness at the end, you can only try to make sure nothing goes wrong from the very beginning.
You have to adopt a defensive mindset when working on deep learning projects. They need sanity checks at each step and attention to every implementation detail. When I started doing deep learning, my workflow was just throwing shit on the wall and seeing what sticks. For me, writing software was always about throwing together a crude piece of code and then beating it into shape gradually. That doesn’t fly here in deep learning.
The Ladder of Abstraction
In general software development, you can add complexity in bulk and in no strict order. You can rely on the compiler, unit tests, or even the IDE to direct our attention to the cracks and faults. You can “move fast and break things”. However, when developing deep learning systems you must methodically move up the ladder of abstraction. You have to step up the complexity one rung at a time. Before you take another step, you must check your foothold to make sure the last step does not yield.
Scientific Method
My workflow is roughly based on the scientific method - hypothesis, experiment and analysis. Before committing any piece of code, I make a hypothesis of how the system should behave, do some experiments to verify the behaviour and investigate if they fail. It may sound extravagant in principle but it is quite simple in practice. The idea is to use small successive experiments as unit tests. In the following sections, I will walk you through the project life cycle.
1) Acquire Mental Model of the Data
Before you build models that learn from the data, you must build a mental model of the data yourself. Know thy data. Perform exploratory data analysis, ideally in a notebook named “01-EDA.ipynb”. For example, visualize the data distributions and identify outliers. Look for inconsistencies like mislabelled training examples. Identify patterns in the data that will be useful for the model to learn. Find out the cases that will be challenging for the model to learn. To build a model, be the model.
2) Prepare Lean Train-Test Framework
In deep learning datasets are big, models are deep and training times are long. For rapid prototyping and experimentation, prepare a small but representative sample of the dataset. Fix a single test batch to visualize prediction dynamics during training. Finally, set up a train-test pipeline for a toy model. Check if everything works as expected.
3) Build Baseline Models
Ideally, you should know the human performance baseline on the task. If not, you can get a rough idea by making predictions on a test batch yourself. The human baseline or even a rough proxy will give you an upper bound to strive towards. Also, make sure to monitor human interpretable metrics like accuracy instead of loss functions like cross-entropy. Loss functions used to train the network are chosen with differentiability in mind, not interpretability.
Now that you know the upper bound of performance, it’s time to set a lower bound. Start with simple models. Most of the times a common-sense heuristic, like recommending the most popular items, serves as a strong lower bound. Now that the upper and lower bounds have set the stage, it’s time for your deep learning models to perform, right? Not yet.
4) Perform Sanity Checks
Insanity is just one .view() away. With deep learning projects, it pays to be paranoid. Here is a handy list of checks:
- Randomness: Make sure to fix the random seeds. Remove as many factors of variation as possible.
- Initial Loss: Given random initialization, the loss must start at some expected value. For example, the default value of cross-entropy loss can be computed based on the class distribution.
- Forward Pass Walkthrough: Print the data shape, mean and variance at every step of the forward pass. Visualize the raw data when it goes into the model and the predictions that come out of the model.
- Backward Pass Walkthrough: Inspect gradients starting backwards from the final layer. Check the mean and variance. The mean should be reasonably centred around zero. If the variance gets smaller and smaller at every backward step, you have vanishing gradients.
- Too stupid to learn: Your model should be able to overfit on a single batch. If not, increase the capacity of the model - add more layers. Train it for longer, change the learning rate or reduce the batch size. If it still doesn’t overfit, brace yourself. Winter is debugging.
5) Overfit-Regularize-Repeat
If all goes all, you can bring out the deep models. I follow a cycle of overfitting and regularization. At first, I unleash a powerful model to boost the training metric. Then I tame the model complexity to raise the validation metric.
Don’t be a hero at the start. Begin with an architecture that is standard for your task. Simply copy the best hyperparameters from the related paper. Use pre-trained models if available. Gradually add complexity to make the model fit the training set. At this stage, you should focus exclusively on improving the training metric. When the validation metric keeps getting worse, your model is finally overfitting.
Now, you can use regularization to exchange some of those gains on the training metric in return for gains in the validation metric. One sure way is by adding more training data. The second best option is data augmentation. If these options are unavailable, you can fall back on the usual regularization tricks: dropout, weight decay, etc.
Go through as many cycles of overfitting & regularization as required. In the final step, do not overfit on the training data. Track the validation metric to stop training early. If you want to win Kaggle competitions, do not forget to ensemble many such models.
Project Organization
Before any of the above, you must organize your project. Experiments should be reproducible. You should be able to try new ideas quickly. All results - successful or not - should be logged. The following structure has served me well.
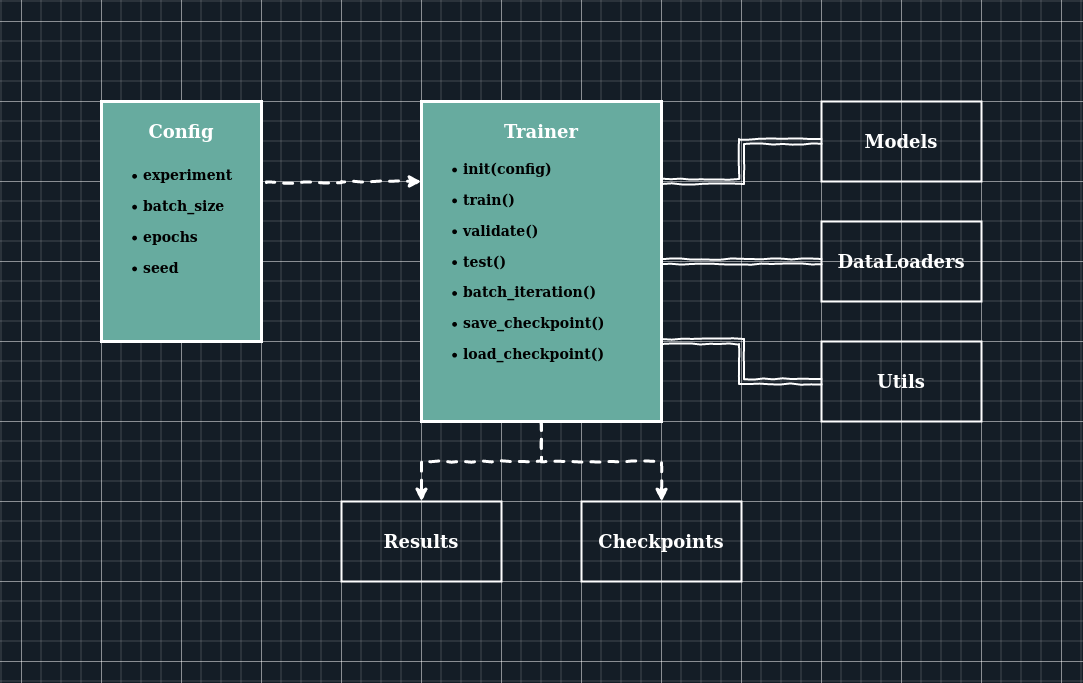
Trainers: A central manager that loads the data and initializes the model based on the given configuration. It takes care of the train-test routine, checkpointing, logging and saving its state when manually interrupted.
Configs: An experiment configuration system is key to reproducibility. I record the hyperparameters of different experiments in different python dictionaries. The trainer only needs this config dictionary, instead of command-line arguments for each hyperparameter. I have found it easier to maintain a master config for the common settings and use smaller configs to define settings specific to each experiment.
Notebooks: Jupyter notebooks can be excellent research and development tools - if used correctly. For example, the pre-processing pipeline can be executed in a notebook first and then modularized into scripts. You can build a new model architecture and test it on a small batch in a notebook first. Literate programming is the key. Name each notebook like journal entries. Use headings, sub-headings and lots of prose to guide the execution flow within a notebook. Write to think better.
Final Remarks
However, take care not to optimize the system design prematurely. Do not attempt to generalize until you know your problem space fairly well. Go from special to general. The same rules for writing software still apply. Except we have solidified abstractions in standard software. They can be used like Lego blocks. However, building deep learning systems is like stacking rocks. Be mindful.
